Solr Resiliency in Production Kubernetes
Some people complain about Solr for Sitecore but I kind of like it. I mean, this is a full-blown enterprise-grade search solution that just plugs right into Sitecore. The Sitecore Content Search API might be another story, but Solr, especially for enterprises, is a natural fit.
For all us Windows/.NET people, Solr is scary because it runs on Java (spooky!) and you have to manually edit configuration files (no checkboxes?) and it executes on the command line (NO GUI?!). It’s hard enough for us terminal-challenged developers to install it in Windows, now you’re being asked how to implement and scale it!
Production, as we all know, is a different beast from local development environments. Let’s jump right into it.
SolrCloud
Don’t be deceived by the name, SolrCloud isn’t some kind of SaaS product for Solr and doesn’t even have anything to do with the cloud actually. Take it up with the Java people, I don’t make the names. SolrCloud is basically scaled Solr.
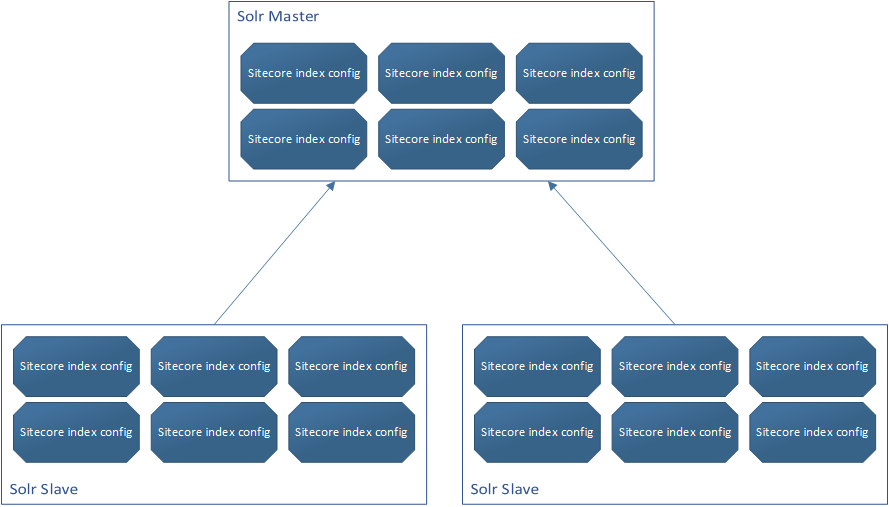
In the olden days, you scaled Solr by designating one instance as master and the other instances as slaves (not woke, I know) and the slaves are periodically polling the master for changes to the Solr indexes, then syncs those changes to itself if it detects and changes. The slave instances effectively become read-only instances but can be scaled to handle large amounts of query traffic.
In modern day Solr, a new application called Zookeeper is introduced. The responsibility of Zookeeper is to keep and maintain configuration, and in the case of Solr (Zookeeper can be used for other purposes as well), it maintains the configurations for the Solr indexes. You send your index configuration to Zookeeper, then Zookeeper is responsible for distributing all that configuration to the Solr instances. This makes scaling horizontally easy as well, since all you’d have to do is spin up a new Solr instance and subscribe it to the Zookeeper instance and it would effectively self-configure.
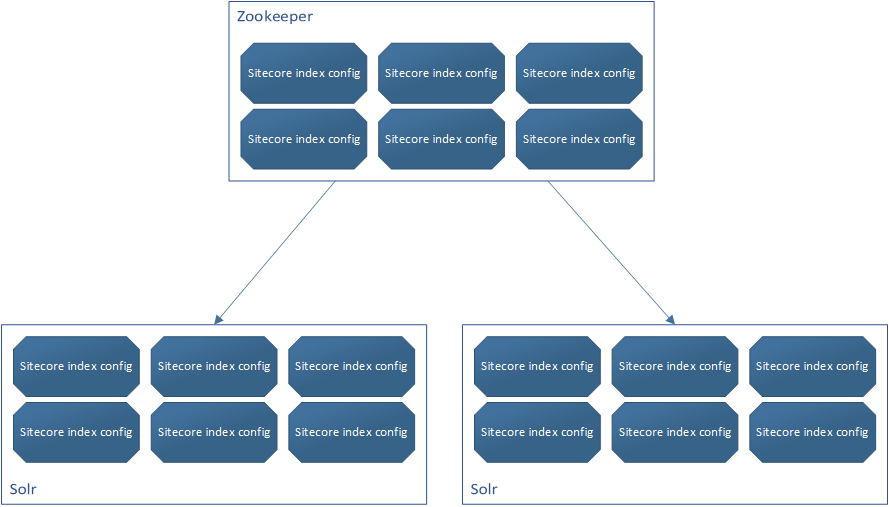
tl;dr - SolrCloud = Solr + Zookeeper
Crash course on Solr in Kubernetes
In Kubernetes, each physical (or virtual) host in the cluster is called a node - a Kubernetes instance consists of a control plane and 1 or more nodes. On each node, you can deploy one or more containers together as a service called a pod - pods are then distributed (“scheduled”) on your nodes based on need.
For a Solr instance, we’ll need a Solr pod and a Zookeeper pod that is scheduled across nodes. Zookeeper will run and the Solr instances will subscribe to the Zookeeper instances to retrieve configuration.
Resiliency
So knowing all this, how do we achieve resiliency for Solr? We’ll definitely want SolrCloud. We’ll want multiple Zookeeper instances (an “ensemble”) and multiple Solr instances. We’ll also want several nodes in our Kubernetes cluster so that we’re not dependent on a singular machine regardless of virtual or physical. Each of the pods should be scheduled to separate nodes.
A 3 node Kubernetes cluster for Solr can look something like this:
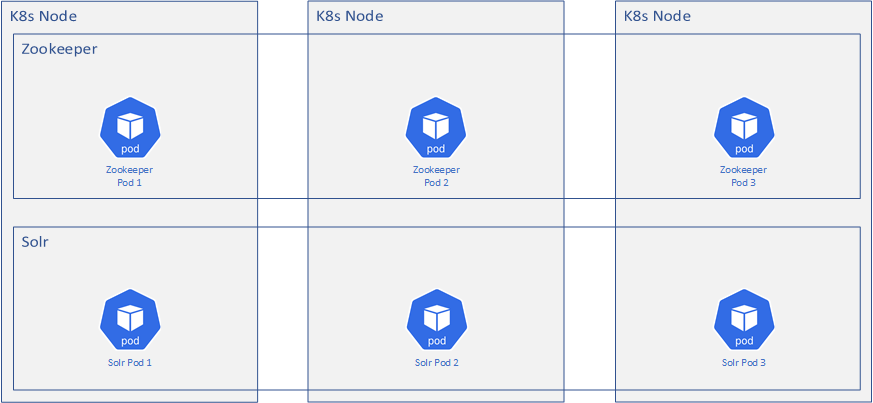
It’s all looking good! However, what happens when something bad happens? Let’s look at the following scenarios:
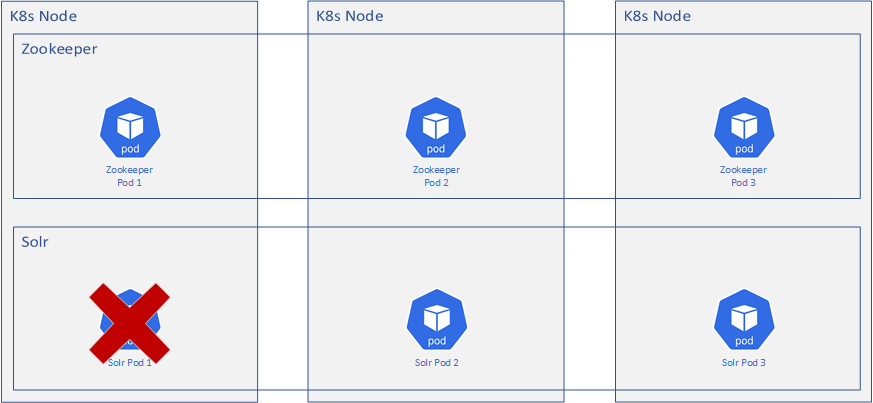
A Solr container dies
Kubernetes handles this - it’s one of the things it does well. If a Solr instance a.k.a. container dies for whatever reason, Kubernetes recognizes this and spins up a new one. Since Zookeeper maintains the configuration, the new Solr instance should retrieve configuration from Zookeeper and it’s back in business. Kubernetes will load-balance the requests across the pods so there shouldn’t be any downtime (unless all the Solr containers die).
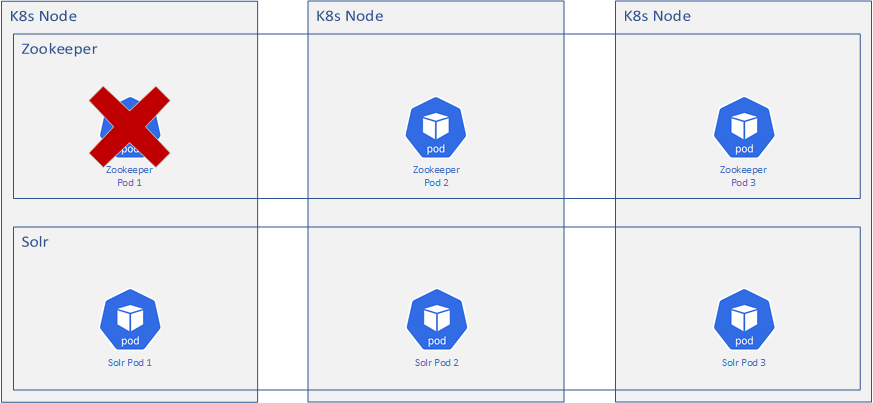
A Zookeeper container dies
Similar to the Solr containers, Kubernetes works its magic and tries to spin up a new container. Zookeeper is interesting though - when you scale Zookeeper, it requires a majority of the configured Zookeeper instances to still be up in order to elect a “leader”, that is, an instance that is the primary instance. In order to have a majority after a failure, you need to have at least 3 instances (a “quorum”) so that if an instance fails, there will still be 2 instances remaining which is a majority. This majority is required for the remaining instance to elect a leader. It’s all very political and somewhere in there there’s probably some weird electoral collge math going on.
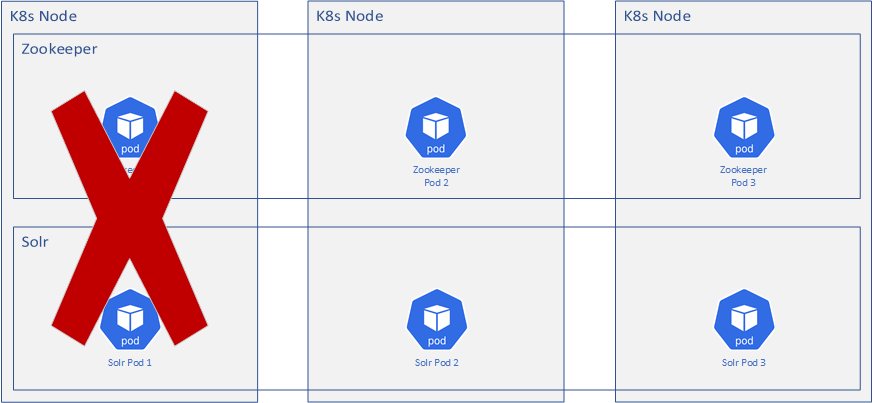
A Kubernetes node dies
This is the fun one. What if an entire Kubernetes node dies? Well, since we’ve got everything scheduled across all of the nodes, we’re just down to 2 instances each of Solr and Zookeeper. Hey look, we’re still okay. We’ve got a Zookeeper majority to elect a new leader and we’ve got Solr still chugging away. Since all the cores and data are stored in persistent volumes, Solr can pick up and keep going while the affected node is fixed or recreated. Depending on the scheduling rules for the pods, Kubernetes may spin up a replacement instance on one of the existing nodes, bringing it back to 3 before the 3rd node is back.
Wrapping Up
This talks about the bare minimum for scaling a resilient SolrCloud instance. You can always have more nodes, more pods on each node, more of everything. The above minus the Kubernetes-related stuff works for non-Kubernetes instances too - the same rules apply for Zookeeper and leader elections and replication and such even if you have separate servers for each instance. Kubernetes is cool because it can do a lot of self-healing but you’ve got to make sure your SolrCloud instance is configured to take advantage of it!